Les types de données en Rom-Hacking, dans le langage C
La GBA, comme toute autre plateforme, est capable de manipuler des données de différentes tailles, et de différents types. Ces types de données sont utilisés pour représenter des informations dans le code, et la manière dont ces informations sont stockées en mémoire. Même si, je le rappelle, la connaissance du langage C n'est pas strictement nécesssaire, connaître les types de données est néanmoins crucial pour comprendre comment le code opère, comment la GBA fonctionne, etc. C'est pour ça que les types de données font partie des bases du source-hacking, et que je les aborde dans cet article.
I. Signe
Dans le reste de cet article, je parlerai souvent de "signé" et "non-signé". Pour qu'il n'y ait pas de confusion, voici un tableau pour décrire ces termes:
| Terme | Signification | Si valeur = valeur - 1 et valeur < MIN | Si valeur = valeur + 1 et valeur > MAX |
|---|---|---|---|
| Signé | Supporte les valeurs négatives. | UB1 | UB1 |
| Non-signé | Ne supporte pas les valeurs négatives. | valeur = MAX | valeur = MIN |
INFO
MIN et MAX représentent respectivement la valeur minimale, et la valeur maximale d'une intervalle de valeurs autorisées pour un type de données.
Exemple: [0, 127] <=> MIN = 0, MAX = 127
II. Les types primitifs
1. L'octet, byte
C'est la plus "petite" unité de donnée manipulable par la GBA. Pensez-en comme une case avec quelque chose dedans, et cette case est la plus petite que peut manipuler votre console. Un octet est égal à 8 bits, et en Anglais, un octet est effectivement un byte (les deux seront utilisés interchangeablement). Plusieurs types de données correspondent à un octet, et la plupart sont répertoriés dans le tableau suivant:
| Type | Signé | MIN | MAX |
|---|---|---|---|
s8 | Oui | -128 | 127 |
u8 | Non | 0 | 255 |
char | ?2 | -128 | 127 |
2. Le demi-mot, half-word
Un demi-mot est égal à 2 octets, ou 16 bits. Plusieurs types de données correspondent à un demi-mot, et la plupart sont répertoriés dans le tableau suivant:
| Type | Signé | MIN | MAX |
|---|---|---|---|
s16 | Oui | -32768 | 32767 |
u16 | Non | 0 | 65535 |
short | ?2 | -32768 | 32767 |
3. Le mot, word
Un mot est égal à 4 octets, ou 32 bits. C'est le type de données natif de la GBA, et l'utiliser un maximum est généralement préférable. Plusieurs types de données correspondent à un mot, et la plupart sont répertoriés dans le tableau suivant:
| Type | Signé | MIN | MAX |
|---|---|---|---|
s32 | Oui | -2147483648 | 2147483647 |
u32 | Non | 0 | 4294967295 |
int | ?2 | -2147483648 | 2147483647 |
T* | ?2 | ? | ? |
INFO
T est un type quelconque, et T* est un pointeur vers ce type. Les pointeurs sont abordés un peu plus bas.
4. Le double-mot, double-word
Un double-mot est égal à 8 octets, ou 64 bits. Etant le double du type natif de la GBA, la manipulation d'un double-mot requiert deux registres. Plusieurs types de données correspondent à un double-mot, et la plupart sont répertoriés dans le tableau suivant:
| Type | Signé | MIN | MAX |
|---|---|---|---|
s64 | Oui | -9223372036854775808 | 9223372036854775807 |
u64 | Non | 0 | 18446744073709551615 |
long long | ?2 | -9223372036854775808 | 9223372036854775807 |
Voici une illustration de la représentation de ces types de données en mémoire, les case avec le o au milieu représentent des octets. 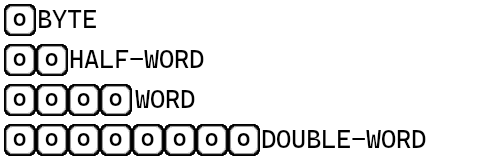
5. Les bits
Ayant techniquement menti à propos de l'octet étant la plus petite unité de donnée, j'apporterai alors une petite précision à propos des bits. Un octet est la plus petite unité de donnée adressable par la GBA, ce qui veut dire que la console ne peut pas déclarer une variable de type "bit", ou manipuler directement des bits. Il est cependant possible de manipuler les bits d'un type de données spécifique, en utilisant des opérations de bitwise (AND, OR, XOR, LSHIFT, RSHIFT, etc.).
III. Les structures
Le second type de données qu'on va voir est la structure, ou struct. Une structure est un type de données personnalisé, défini par le programmeur, qui regroupe plusieurs autres types de données (pouvant être primitifs, ou non), ces données, dans la mémoire, sont placées l'une à côté de l'autre dans l'ordre de déclaration. Une structure est introduite avec le mot-clé struct, suivi du nom de la structure, et d'un bloc de code entre accolades qui contient les membres de la structure. Par exemple:
struct Foo
{
int a;
short b;
char c;
char d;
};En se basant sur les tailles des types vues précédement, et en supposant que le compilateur n'ajoute pas de "padding"3 (des octets vides pour aligner les données), la structure Foo serait représentée en mémoire de la manière suivante: 
NOTE SUR LES STRUCTURES
Les structures peuvent aussi être composées de bits, et un bit composant une structure est appelé un "bit-field". Un bit-field est défini en spécifiant le nombre de bits qu'il occupe après le type de données. Par exemple:
struct Bar
{
unsigned int a : 3; // Ce bit-field occupe 3 bits
unsigned int b : 5; // Ce bit-field occupe 5 bits
};Dans cet exemple, la structure Bar possède un membre a de 3 bits, et un membre b de 5 bits, ce qui fait que la structure Bar occupe un total de 8 bits, soit 1 octet.
IV. Les unions
Le troisième type de données qu'on va voir est l'union, ou union. Une union est similaire à une structure, mais avec une différence clé: tous les membres d'une union partagent le même espace mémoire. Cela signifie que la taille d'une union est égale à la taille de son membre le plus grand, c-à-d qu'au lieu d'être placées l'une à côté de l'autre, elles sont placées exactement au même endroit en mémoire. Une union est introduite avec le mot-clé union, suivi du nom de l'union, et d'un bloc de code entre accolades qui contient les membres de l'union. Par exemple:
union Baz
{
int a;
short b;
char c;
char d;
};Pour reprendre l'exemple de la structure Foo, la union Baz serait représentée en mémoire de la manière suivante, avec les cases en gris clair représentant les octets partagés par tous les membres de l'union: 
NOTE SUR LES UNIONS
- Les unions sont paddées de la même manière que les structures afin d'aligner les données, et éviter les pénalités de performance.
- Il est souvent déconseillé de lire un membre d'une union différent de celui qui a été écrit en dernier, même si dans le cas de la
GBA, c'est juste une lecture d'octets dans un "différent format".
V. Les enumérations
Les enumérations, ou enum, sont un type de données personnalisé qui permet de définir un ensemble de constantes symboliques. Chaque constante dans une énumération est associée à une valeur entière, et par défaut, la première constante a la valeur 0, chaque constante la suivant a une valeur incrémentée de 1. Une énumération est introduite avec le mot-clé enum, suivi du nom de l'énumération, et d'un bloc de code entre accolades qui contient les constantes de l'énumération. Par exemple:
enum Color
{
RED, // RED = 0
GREEN, // GREEN = 1
BLUE // BLUE = 2
};Les enumérations occupent le même espace mémoire que le word (4 octets), et les constantes de l'énumération sont généralement utilisées pour améliorer la lisibilité du code, en remplaçant des valeurs entières par des noms plus significatifs.
VI. Les pointeurs
1. Les pointeurs à proprement parler
Un pointeur est un type de données de la taille d'un word (4 octets), qui contient l'adresse mémoire d'une variable. Une adresse mémoire est "l'endroit" en mémoire où se trouve la case mémoire d'une valeur, de cette relation, un pointeur a aussi une adresse, et c'est ainsi qu'on peut obtenir des pointeurs de pointeurs, et ainsi de suite. Un pointeur est introduit en spécifiant le type de données pointé, suivi du nom du pointeur, et d'un astérisque. Par exemple:
u8 *ptr = NULL; // Déclaration d'un pointeur vers un `u8`, initialisé à `NULL` (0x00000000)Un pointeur initialisé à NULL est un pointeur qui ne pointe vers aucune adresse mémoire valide, et il est généralement utilisé pour indiquer qu'un pointeur n'est pas encore assigné à une variable spécifique. La représentation en mémoire d'un pointeur pointant vers NULL serait la suivante: 
Les cases du pointeur contiennent une valeur, un entier non-signé de 4 octets, qui représente l'adresse mémoire vers laquelle le pointeur pointe. Par exemple, si ptr pointe vers une variable de type u8 située à l'adresse 0x02000000, la représentation en mémoire serait la suivante: 
Les pointeurs sont utilisés pour accéder à des variables de manière indirecte, pour manipuler des tableaux, pour passer des arguments à des fonctions, etc. Ils sont un concept fondamental en programmation en C, et leur compréhension représente un avantage significatif pour le source-hacking.
NOTE SUR L'ARITHMETIQUE DES POINTEURS
Les opérateurs arithmétiques (+, -, ++, --, etc.) peuvent être utilisés avec des pointeurs pour manipuler les adresses mémoire. Cependant, toute opération est effectuée en fonction du type de données pointé.
Comme règle générale, pour connaître l'adresse à laquelle le pointeur va pointer, on utilise la formule suivante:
T *ptr;
T *newAddress;
// ...
u32 uPtr = (u32) ptr; // On convertit le pointeur en un entier non-signé de 4 octets pour effectuer l'opération arithmétique.
u32 uN = (u32) n; // On convertit la deuxième opérande en un entier non-signé de 4 octets pour effectuer l'opération arithmétique.
newAddress = (T *) (uPtr `op` uN * sizeof(T)); // `op` représente l'opérateur arithmétique, et `n` représente la deuxième opérande.2. Les tableaux
Les tableaux sont un type de données qui permet de stocker une collection d'éléments du même type. Un tableau est contigu en mémoire, alors les éléments sont stockés les uns à la suite des autres. Un tableau est défini en spécifiant le type des éléments, suivi du nom du tableau, et du nombre d'éléments entre crochets. Par exemple:
u32 numbers[5]; // Déclaration d'un tableau de 5 entiersLes tableaux sont en réalité des pointeurs vers le premier élément du tableau, et l'opérateur de subscript [] est une indirection de l'arithmétique des pointeurs. Par exemple: numbers[2] est équivalent à *(numbers + 2).
ATTENTION
- Les tableaux sont indexés à partir de
0, ce qui signifie que le premier élément du tableau estnumbers[0]. - Il n'y a aucune vérification de dépassement de tableau en
C, l'accès à un élément en dehors des limites du tableau estUB, et peut entraîner des conséquences imprévisibles.
NOTE SUR LES TABLEAUX
Selon les propriétés de l'opérateur de subscript, on peut écrire du code tel que:
u8 foo[3] = {1, 2, 3};
// Comme a[b] équivaut à *(a + b), alors:
foo[1] == *(foo + 1) == 1[foo] == *(1 + foo) == 2;C'est aussi à cause de ces propriétés que les tableaux sont indexés à partir de 0, puisque foo[0] équivaut à *(foo + 0), ce qui est égal à *foo, et donc au premier élément du tableau.
3. Les pointeurs de fonctions
Une fonction, sans trop entrer dans les détails, est un bloc de code qui effectue une tâche spécifique, et qui peut être appelé à partir d'autres parties du code. Un pointeur de fonction est un type de données qui contient l'adresse d'une fonction, et il peut être utilisé pour appeler la fonction pointée. Un pointeur de fonction est défini en spécifiant le type de retour de la fonction, suivi du nom du pointeur, et de la liste des paramètres entre parenthèses. Par exemple:
R (*functionPointer)(A, B, ...); // Déclaration d'un pointeur de fonction qui pointe vers une fonction qui prend des arguments, et retourne une valeur de type `R`.VII. Les alias
Un alias est un autre nom pour un type de données. Cet alias permet de référencer un type de données d'une manière plus intuitive, ou plus adaptée selon le contexte. Un alias est introduit avec le mot-clé typedef, suivi du type de données à référencer, et du nom de l'alias. Par exemple:
typedef u16 COLOR; //!< Cet alias permet de référencer un `u16` en tant que `COLOR`, ce qui est plus intuitif dans le contexte de la manipulation des couleurs.
COLOR RGB(u8 r, u8 g, u8 b)
{
return r | (g << 5) | (b << 10);
}Notes
| Note | Explication |
|---|---|
| 1 | UB (Undefined Behavior) signifie, littéralement, "comportement indéfini". Cela implique que dans ce scénario, ce qu'il se passe n'est pas établi dans la standardisation du langage C, alors le compilateur est libre de faire ce qu'il veut (faire planter le jeu, supprimer la save, etc.). |
| 2 | Ce comportement est défini par l'implémentation du compilateur. |
| 3 | Le "padding" est une technique utilisée par les compilateurs pour aligner les données en mémoire, ce qui peut améliorer les performances d'accès. |